随着科技的不断进步,曾经辉煌夺目的PC时代,也被渐渐崛起的手机移动端取代,互联网也显得特别的浮躁,生怕被时代所抛弃,以致于相对见效慢的SEO优化手法越来越不被主流所推崇,使得除了医疗、旅游、电商、房产等一些大型网站的SEOer保持了应有的尊严,其他行业。
尤其是传统企业的SEOer的位置也略显尴尬,要么就被公司奉为“神”一样的人物,既要会SEO,又要会SEM,在SEM广告点击单价提高后,那么就要会信息流了,还要兼职做信息流的广告图,在繁杂的工作中迷失自我,经常扎心自问,我到底是个啥;要么就不被公司重视,放在一个可有可无的位置。
于是, SEOer们也渐渐的在寻求着改变 ,往运营、产品、新媒体、文案等互联网相关的岗位转型,有些在转型中找到了自我,而有些在转型中却更加的迷惘。
下面一起看看我们曾经走过的那些年代SEO内容堆砌时代
TF-IDF(词频-逆文档频率)算法是一种统计方法,用以评估一字词对于一个文件集或一个语料库中的其中一份文件的重要程度。字词的重要性随着它在文件中出现的次数成正比增加,但同时会随着它在语料库中出现的频率成反比下降。该算法在数据挖掘、文本处理和信息检索等领域得到了广泛的应用,如从一篇文章中找到它的关键词。
TFIDF的主要思想是:如果某个词或短语在一篇文章中出现的频率TF高,并且在其他文章中很少出现,则认为此词或者短语具有很好的类别区分能力,适合用来分类。TF-IDF实际上就是 TF*IDF,其中 TF(Term Frequency),表示词条在文章Document 中出现的频率;IDF(Inverse Document Frequency)。
其主要思想就是,如果包含某个词 ,Word的文档越少,则这个词的区分度就越大,也就是 IDF 越大。对于如何获取一篇文章的关键词,我们可以计算这边文章出现的所有名词的 TF-IDF,TF-IDF越大,则说明这个名词对这篇文章的区分度就越高,取 TF-IDF 值较大的几个词,就可以当做这篇文章的关键词。
基于TF-IDF算法衍生出来的内容堆砌时代,在这个时期盛行各种伪原创工具,堆积关键词密度,站长之家的密度建议2%至8%被誉为行业标准,还有四处一词(标题title、关键词keywords和描述description、内容、锚文本)的运用,让SEOer们在搜索引起中如鱼得水。
SEO外链时代:
PageRank,网页排名,又称网页级别、Google左侧排名或佩奇排名,是一种由根据网页之间相互的超链接计算的技术,而作为网页排名的要素之一,以Google公司创办人拉里·佩奇(Larry
Page)之姓来命名。
Google用它来体现网页的相关性和重要性,在搜索引擎优化操作中是经常被用来评估网页优化的成效因素之 一。Google的创始人拉里·佩奇和谢尔盖·布林于1998年在斯坦福大学发明了这项技术。
PageRank通过网络浩瀚的超链接关系来确定一个页面的等级。Google把从A页面到B页面的链接解释为A页面给B页面投票,Google根据投票来源(甚至来源的来源,即链接到A页面的页面)和投票目标的等级来决定新的等级。简单的说,一个高等级的页面可以使其他低等级页面的等级提升。
基于PageRank算法衍生出来的外链时代,那时候多浏览器多窗口同时运行,CtrlC加CtrlV无限循环,我们被亲切地称为CV工程师;而后黑马博客群发、虫虫营销助手,又如剑客手中的剑摄取着搜索引擎这个大流量池;当然还有大量的各式各样友情链接交换手法以及链轮手法。
SEO点击时代:
随着搜索引擎的算法机制越来完善,渐渐减弱对内容密度、外链的比重,倡导用户体验优先,那么点击算法孕育而生,由用户点击次数跟用户停留时间构成。
用户点击次数:
尽量控制点击次数,要和人为的点击比较接近(每个关键词点击在2-5次左右),从百度页面点击进去关键词网站页面,待2-10秒(页面不要关闭,时间待调整),再次从百度搜索进入,点击关键词页面进入网站,待10秒左右,并且最好可以再点击几次页面内的其他链接。确保整个过程用户停留在网站的时间大于1分钟以上。
用户停留时间:
论坛最佳时间在3分钟左右,门户资讯网站一般在1分钟-3分钟左右。
纵观SEO大神们众说纷纭的论点,我个人还是比较推崇:
SEO流量≈搜索需求覆盖率*收录量*排名*点击率
所以,接下来将会针对这四个因素具体叙述。
1.搜索需求覆盖率
搜索需求覆盖率简单可以理解为词库,也就是说针对于自身行业建立词库需求表,那么可以通过以下几种途径去寻找关键词:
1) 百度相关搜索
2) 百度下拉框
3) 关键词规划师(http://www2.baidu.com/)
4) 5118(http://www.5118.com/)
5) 词库网(http://www.ciku5.com/)
6) 爱站词库(https://ci.aizhan.com/)
7)搜狗输入法词库(https://pinyin.sogou.com/dict/)
8)对手网站建立标签词库
建立词库需求表有两个作用:
1) 针对词库关键词去创造(采集)内容
2) 相近属性(词义)的关键词组成聚合(TAG)页
例如:怎样让皮肤变白_怎样使皮肤变白_皮肤黑怎么变白
其实这些词的意思是差不多的,这样组成在一定程度上满足了更多的人的搜索需求。
2. 收录量
收录量≈内容数量*内容质量1)内容数量
a.采集法:采集法采集的内容质量相对较低,但是可以量取胜,把之前整理好的词库按照词性相近的原则,生成聚合页。演示思路如下:
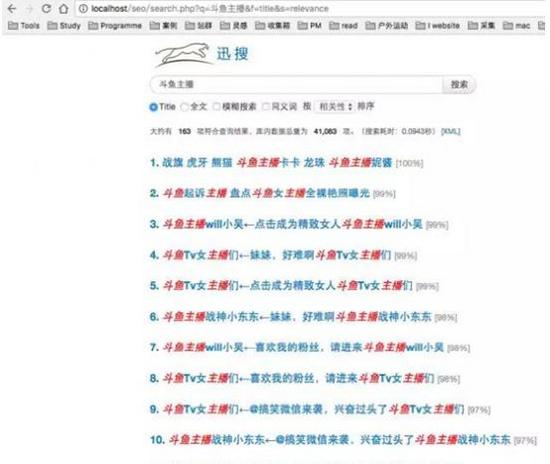
第一步,假定做一个娱乐网站,在搜索引擎上搜索“娱乐”二字,挖掘出对手网站,把网址记录下来。
第二步,把记录的网址放到5118、爱站、站长网挖掘出有排名的关键词,然后把这些关键词都导出来,这边5118为例。
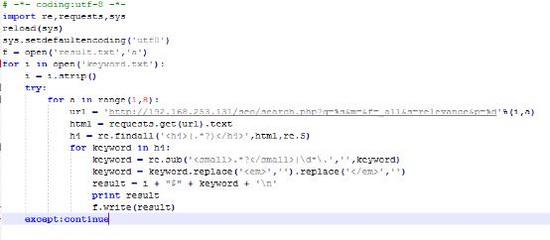
第三步,导出来的关键词肯定是有凌乱的,那么我们根据词性就行分类,选取每个关键词的核心词,这里需要借用Python的第三方库textrank4zh,代码参考如下:
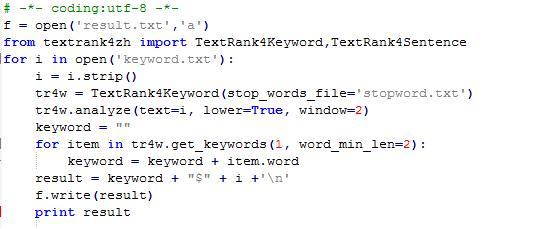
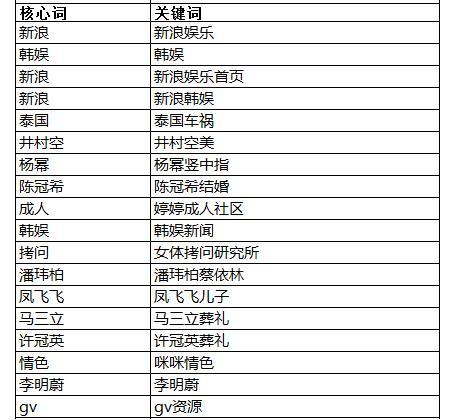
然后通过整理之后,得出结果,包含核心词跟关键词。
最后,通过VB工具,得出最终结果,同一个核心词都会显示在一列,那么这一列的关键词,我们就可以认为是相同词性的词,可以作为构成同一个标签(TAG)页。
第四步,根据标签页的关键词去采集内容,建议选择同一个标签页字符数最少的关键词,采集内容的渠道可以是今日头条,各大新闻网站,或者资讯类APP,具体怎么采,可以翻开《 抓了10W条数据,分析了1W个爆文,写出了10W阅读的内容 》里面的代码。
第五步,采集好内容之后,那么就可以构建是本地化搜索引擎,如火端搜索,xunsearch等,然后把内容导入本地搜索引擎当中,这里以xunsearch为例,虚拟机新建linux系统,搭建xunsearch系统,具体安装可参考《xunsearch安装步骤》,最终得到的搜索引擎如下图,那么就可以把我们的目标关键词放在搜索引擎搜索。
第六步,在虚拟机里面搜索,效率很低,那么可以利用python,用虚拟机IP作为网址,具体代码如下图,那么就可以得到标签关键词对应的文章,生成对应的标签页。
对于有实力的品牌,建议去做个官网认证。
版权声明:版权归原作者所有,如有侵权请联系我们予以删除!转载只为传递更多网络信息。